A Grounded Voice Copilot for 3D Vehicle Inspection
The hard part of a voice copilot for a 3D vehicle is not the voice. Getting a microphone to transcribe “show me the headlights” and pipe it to a model takes an afternoon. The hard part is what happens when the model guesses at the wrong mesh and confirms a change that never happened, and nothing in the interface tells you.
FRIDAY is the inspection copilot in Mobisim, a browser-native 3D vehicle inspection surface. The design question it sits on: how do you make a voice copilot say “I can’t find that” rather than fabricating confidence against a raw GLB it cannot actually read.
The Asset Pipeline
A raw GLB has no concept of “headlights.” It has node IDs, mesh hierarchies, and material assignments. A structural inventory of geometry, not a description of a vehicle. Asking FRIDAY to operate on that directly is asking it to guess.
The pipeline exists to close that gap in two steps.
3D vehicle asset -> structural DAG -> semantic overlay -> active inspection asset
First, structural extraction. The pipeline walks the GLB node hierarchy and catalogs everything: node IDs, mesh details, materials, parent-child relationships. No inference. Pure extraction from the file as authored. This is the map of the territory.
Second, the semantic overlay. It takes that structural map and assigns node IDs to stable vocabulary: wheels, body, lights, glass. This is where Object_412 and its siblings become “front-left headlight assembly.” Persistent, file-backed per asset, built from reviewed assignments rather than raw model output.
At inspection time, both layers load into runtime context. FRIDAY reads that. It does not touch raw mesh names.
The two layers stay separate because they break in different ways. The structural manifest is locked to the GLB: change the asset, regenerate the manifest. The semantic overlay is expensive to rebuild (an LLM pass over the full manifest) and is designed to stay valid across minor asset updates. Collapse them and every staleness check has to reason about both at once. Keep them separate and each has one clear owner.
Execution Model
Every request routes through one of two paths, and the distribution surprised me.
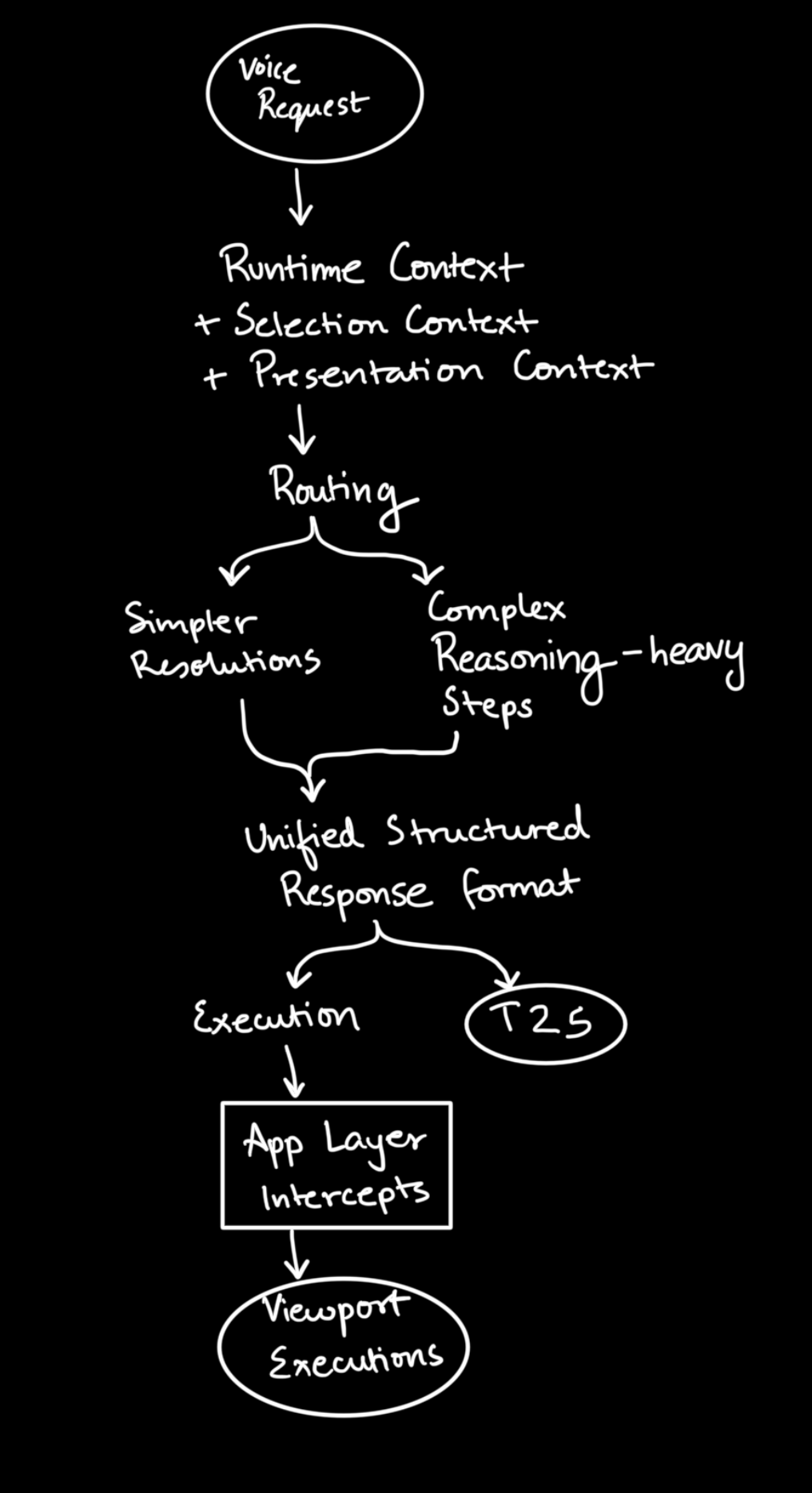
Most requests hit the shortcut path. restore, paint it red, wireframe mode, isolate the wheels. Direct deterministic operations. The LLM is routing, not reasoning. FRIDAY’s model does real work only when the request is genuinely ambiguous, multi-step, or needs semantic lookup — which is less often than you’d expect from a voice copilot.
The reasoning path caps at three tool rounds. Not a resource limit. A signal: more than three rounds means the request has hit missing semantic context, and more computation will not fix that.
Both text chat and voice drive the same executor. Voice is an alternate input surface, not a parallel logic stack. The orb opens a real-time WebRTC session; FRIDAY speaks back through the same session. The debugging consequence: the failure is never “voice is broken.” It is always “the executor is behaving wrong.”
Runtime Context
Three state surfaces feed FRIDAY’s context, and keeping them separate is most of what makes the system predictable.
The most underrated part is cursor selection. Click the rear diffuser, ask “what’s the material on this?” FRIDAY knows what “this” is because the selection was already in context when the request arrived. No re-prompting. No disambiguation round-trip. It is ephemeral and asset-scoped and it does a lot of work quietly.
The presentation layer is reversible client-side visual state: paint, tint, highlight, isolate, X-ray, wireframe. Requests come in through voice or chat and do not mutate Three.js state directly. The app layer intercepts the structured response and applies the patch. If the viewport does not reflect the change, the operation is broken. Sidebars and text are not the proof surface.
The semantic overlay is the durable source of truth for what the asset means. Shared across sessions. The one surface that outlives the session.
Presentation is session-lived. Selection is ephemeral. Semantic state is persistent. Each invalidates on a completely different clock. Flattening them is a slow-motion bug.
The Semantic Authoring Loop
The natural instinct is to let the model generate the semantic overlay and trust it. That instinct is wrong.
LLM proposals are generated candidates, the model’s best guess at grouping node IDs into vocabulary like wheels, body, lights. They go into a separate store and stay there until reviewed. Reviewed assignments are what planners actually read from. Group definitions are shared vocabulary independent of any asset. The overlay FRIDAY uses is rebuilt from reviewed assignments only.
The model proposes. It does not control the overlay.
This is less automated than it sounds, and that is deliberate. The failure mode of trusting raw model output is FRIDAY highlighting Mesh_0412 and confirming with confidence. The failure mode of the review gate is a fresh asset with thin coverage. The second failure is legible. The first is not.
Semantic coverage is the ceiling. A part with no reviewed assignment cannot be resolved by name. The Audi R8 is well-covered because it has been reviewed thoroughly. A fresh asset is not, and the system says so.
The Voice Layer
The orb opens a real-time WebRTC session. Selection and presentation state changes get pushed to the session via session.update as the user interacts, not just when a request arrives. FRIDAY’s context is live.
Orbit the car, click a part, say “what is this?” FRIDAY already knows. The selection was pushed when you clicked. There is no re-prompting round-trip because the context was already there.
If the asset loaded without a reviewed overlay, semantic resolution degrades to structural-only. Back to mesh-name territory. The session says so rather than fabricating semantic knowledge it does not have. Graceful degradation over silent failure.
Where It Still Breaks
The freshness bug is the subtle one. There are two endpoints that both return something called overlayStatus. The /inspection endpoint derives it from structural generation time. The /semantic-overlay endpoint returns the snapshot shape directly. These are not the same concept, and nothing in the shape of the response tells you which one you’re reading.
The failure mode: the system reports the overlay as fresh. A request comes in. FRIDAY resolves a part name confidently. The viewport does not update. The overlay was structurally present but semantically stale, and the freshness check cleared it on the wrong clock. This is not a loud failure. No errors, no warnings. Just a wrong answer that looks like a right one.
The overlay is mutable and shared. Refreshes and semantic mutations both write the same file. Last-write-wins is real. The guardrail is a narrow write path: one connector owns persistence, callers do not touch it directly. It contains the problem, but the freshness split is still there.
At the end of the day…
…this was planned and built in 7 days. The structural pipeline, the semantic authoring loop, the WebRTC voice layer, the execution model, the three-surface state separation — seven days, from blank repo to a live inspection session on an Audi R8.

Swap FRIDAY’s underlying model and the behavioral envelope barely moves. The reliability is not in the model. It is in the structural manifest, the reviewed semantic overlay, the separation of three state surfaces that do not bleed into each other, and an execution model that routes most requests without touching the LLM at all.
Everyone benchmarking models right now is optimizing the wrong variable. Mobisim is a case for asking a different question: what is the model actually allowed to operate on? Build that environment well enough and the model choice becomes a second-order concern.
The viewport is the proof surface. Either it reflects what was asked, or it does not.